Read and Parse Json File in S3
Contents
- one. Introduction
- 2. Reading a JSON file as input from AWS S3 saucepan
- METHOD-ane: Using Native S3 Connexion backdrop
- METHOD-two: Using Coffee and Bureaucracy Parser Transformation
- Step1: Create a template file for Hierarchical Schema
- Step2: Create a Hierarchical Schema
- Step3: Create a Mapping to read JSON file
- I. Configuring Source transformation
- II. Configuring JAVA transformation
- II. Configuring Bureaucracy Parser transformation
- III. Configuring Target transformation
- 3. Reading multiple JSON files every bit input from AWS S3 bucket – Indirect Loading
- four. Determination
1. Introduction
The process to read JSON files from AWS S3 folders using Informatica cloud (IICS) is different from reading JSON files from Secure amanuensis automobile. We have discussed in detail the process to read JSON files from secure amanuensis machine in our previous commodity. In this commodity let usa hash out the step-by-stride process to read a JSON file from AWS S3 bucket and also discuss the process to read multiple JSON files with same structure using Indirect loading method.
2. Reading a JSON file as input from AWS S3 saucepan
For the purpose of demonstration Consider the following every bit the source JSON file information which nosotros want to read and parse through Informatica Cloud.
Contents of writer.json file.
[{ "AUTHOR_UID": ane, "FIRST_NAME": "Fiona", "MIDDLE_NAME": null, "LAST_NAME": "Macdonald" }, { "AUTHOR_UID": 2, "FIRST_NAME": "Gian", "MIDDLE_NAME": "Paulo", "LAST_NAME": "Faleschini" }, { "AUTHOR_UID": 3, "FIRST_NAME": "Laura", "MIDDLE_NAME": "1000", "LAST_NAME": "Egendorf" } ] METHOD-1: Using Native S3 Connexion properties
In the Source transformation, select the Amazon S3 v2 Connectedness and JSON file you wanted to parse as the source object with input file format equally Json .
Under Formatting Options, select the Schema Source as Read from information file and other options with default values. This mode we are asking the Informatica to understand the hierarchy from source file without passing any schema file for reference.
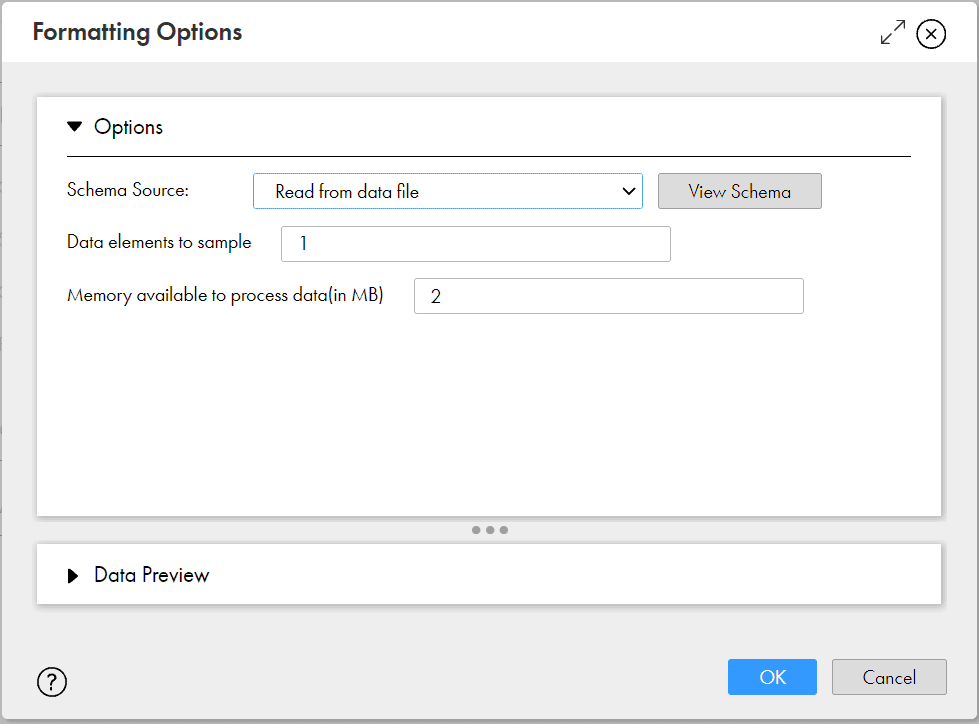
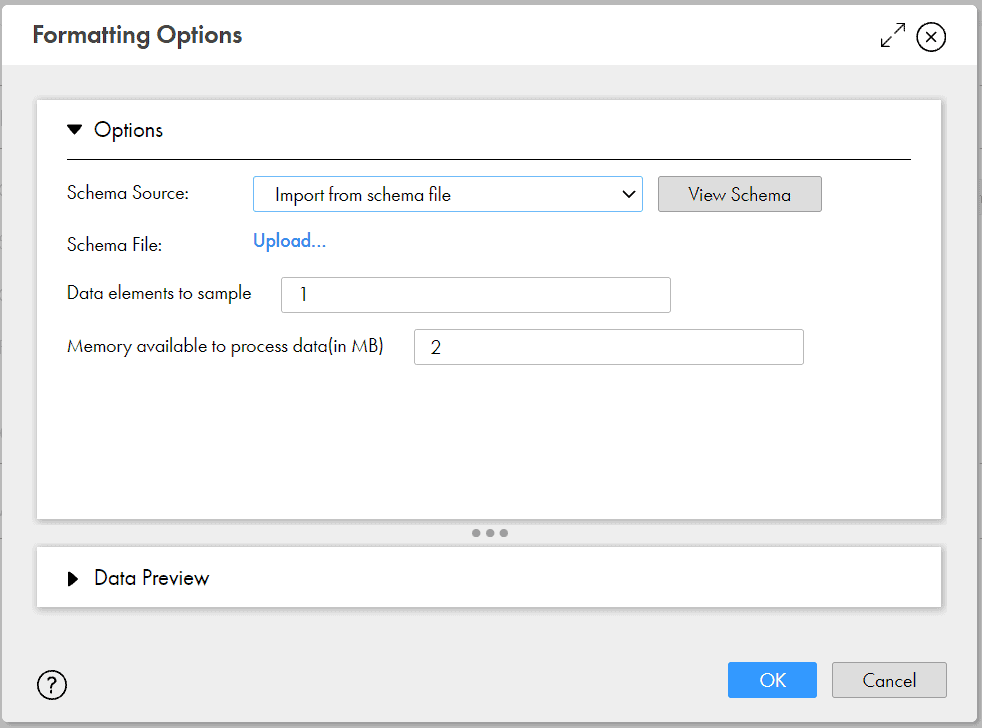
Alternatively, nosotros tin upload a schema file for Informatica to compare and parse the source file past selecting the Schema Source as Import from Schema file.
Under Fields tab of source transformation, nosotros can encounter the relational fields created past Informatica data Integration by parsing JSON file.
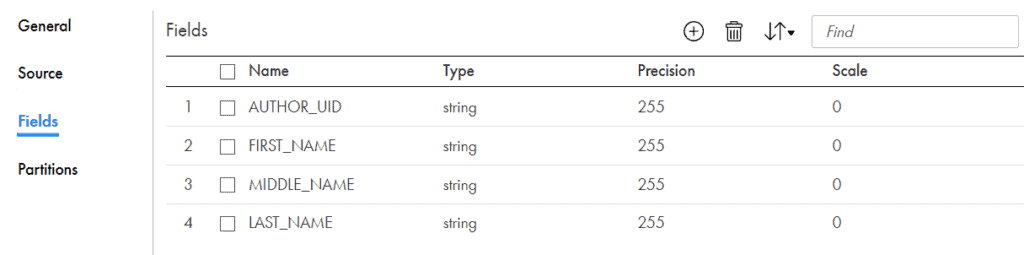
Pass the relational source fields to downstream transformations to further transform as per requirement and load into target.
METHOD-2: Using Java and Hierarchy Parser Transformation
Step1: Create a template file for Hierarchical Schema
Based on the structure of your JSON file, prepare a sample file which defines the schema definition of your JSON file.
From our source data, nosotros can see that it contains array of author details. Each author element in the array consists of iv attributes – AUTHOR_UID, FIRST_NAME, MIDDLE_NAME, LAST_NAME and their corresponding values.
Below template defines the construction of our JSON file.
[{ "AUTHOR_UID": 999, "FIRST_NAME": "f_name", "MIDDLE_NAME": "m_name", "LAST_NAME": "l_name" }] Step2: Create a Hierarchical Schema
Create a Hierarchical Schema using the template file created in the earlier step.
To create a Hierarchical Schema, login to Informatica Cloud Data Integration > Click onComponents > selectHierarchical Schema > clickCreate.
Enter the proper name and description of Hierarchical Schema. Select the JSON sample file created in earlier stride which contains the hierarchical structure of source information. Validate and Relieve the Hierarchical Schema.
Step3: Create a Mapping to read JSON file
I. Configuring Source transformation
In the Source Transformation, select the Amazon S3 v2 Connection and JSON file which you wanted to parse every bit the source object with input file format every bit None .
Under Fields tab of Source transformation, you can run into ii fields. The entire JSON file contents are stored into a unmarried field named data of type binary . The JSON file proper name information is stored into field named FileName of type Cord .

In order to convert the binary information to cord, Java transformation is used.
II. Configuring JAVA transformation
Pass the data from source transformation to Java transformation.
Under Java tab of the transformation, navigate to Import Packages under Go to section.
Under Import Packages of Java Editor enter below text to import java parcel which translates betwixt bytes and Unicode characters.
import java.nio.charset.StandardCharsets; Select On Input Row nether Become to section. Under Outputs tab, create a new field of blazon string to agree the data converted from binary. Ensure proper precision for the field based on your input data, else information truncation would occur.
Under Input Row department of coffee editor, provide the conversion lawmaking as beneath which converts the binary data to string and loads into field Out_String created in earlier stride.
Out_String = new String(information, StandardCharsets.UTF_8); generateRow(); 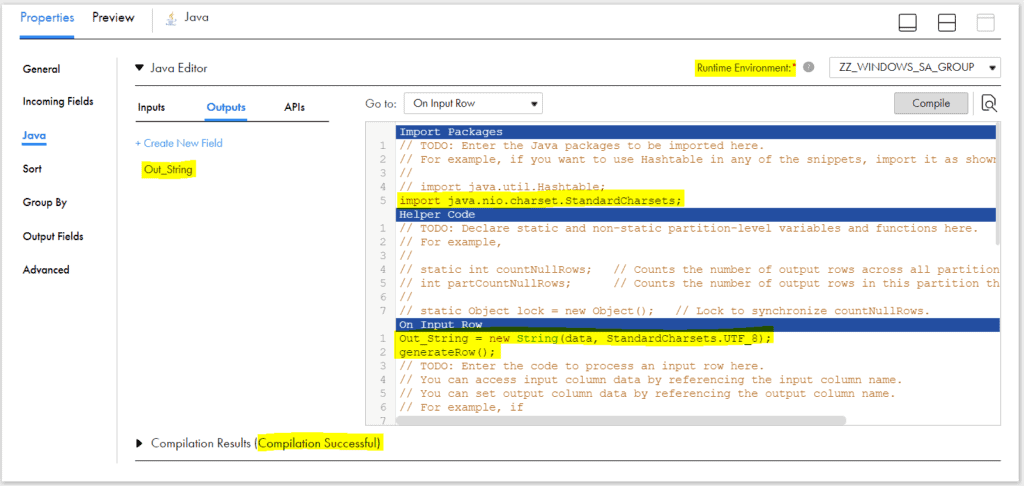
Select the Runtime Environment and click on Compile.
Laissez passer the data to Hierarchy Parser transformation in one case compilation is successful.
Ii. Configuring Hierarchy Parser transformation
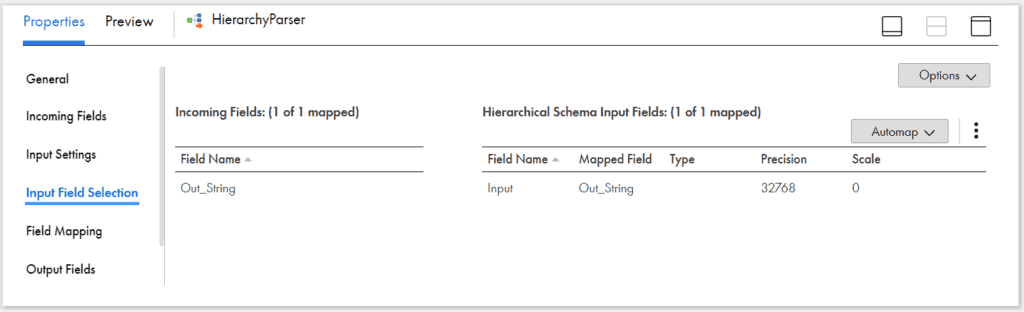
Under Incoming Fields tab of Hierarchy Parser transformation, include but string output from Coffee transformation and exclude other fields.
Under Input Settings tab, select the Hierarchical Schema created in before steps. Select Input Type as Buffer.
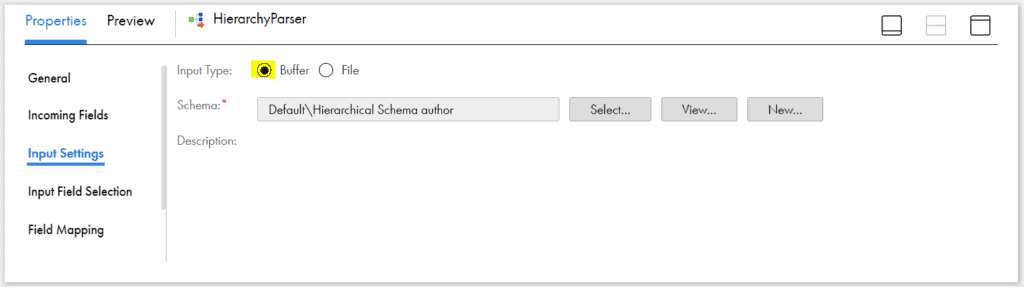
Buffer mode should be selected when the JSON/XML data is in the incoming source cavalcade. File mode should be selected when the JSON/XML data is directly read from a file.
Here we are reading JSON data in the course of a field and hence Buffer mode is selected.
Next under Input Field Choice tab, map the incoming field from Coffee to the Hierarchical Schema Input Field.
Nether Field Mapping tab, map the elements from rootArray to target equally required.
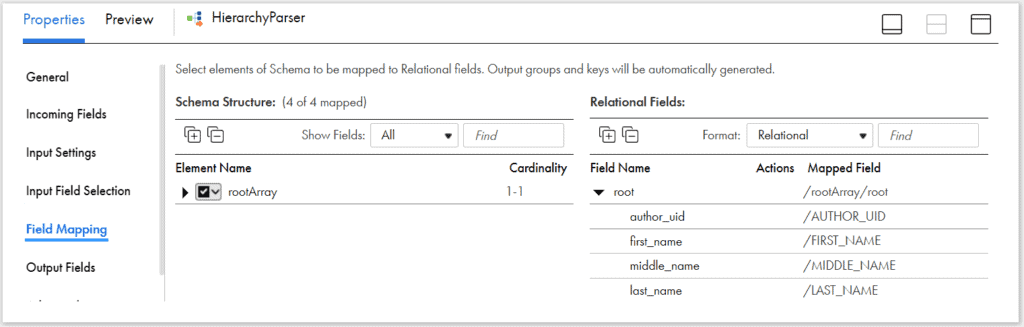
The above shown field mapping implies that now each author element from JSON file will be converted into a unmarried relational output row with column names equally AUTHOR_UID, FIRST_NAME, MIDDLE_NAME and LAST_NAME
III. Configuring Target transformation
Pass the data from Hierarchy Parser to a target transformation.
If your data set contains multiple output groups, map them to advisable downstream transformations and bring together them before passing to target transformation. In our example, we have merely one output which volition exist mapped to target.
The final mapping volition exist as below.

Save and run the mapping. The final output nosotros become will exist as below.
"author_uid","first_name","middle_name","last_name" ane,"Fiona",,"Macdonald" 2,"Gian","Paulo","Faleschini" 3,"Laura","K","Egendorf" iii. Reading multiple JSON files equally input from AWS S3 bucket – Indirect Loading
In our previous article, nosotros have discussed in detail how to perform Indirect loading of AWS S3 files using manifest files. Please refer the linked article for more than information.
In order to read multiple JSON files as input in a mapping, create a manifest file and pass it as source.
Utilise the below format to prepare a manifest file.
{ "fileLocations": [{ "WildcardURIs": [ "directory_path/filename*.json" ] }, { "URIPrefixes": [ "AWS_S3_bucket_Name/" ] }], "settings": { "stopOnFail": "true" } } Select the manifest file as the input in source transformation instead of JSON files with input file format equally None .
The rest of the procedure is same as METHOD-2 explained in above sections of article. Pass the data to Java transformation. Import required packages to convert binary data to cord and pass it to hierarchy parser transformation to parse the JSON input to a relational output.
4. Determination
The Secure Agent requires a Coffee Development Kit (JDK) to compile the Java code and generate byte code for the transformation. Azul OpenJDK is installed with the Secure Agent, so y'all do non need to install a separate JDK. Azul OpenJDK includes the Java Runtime Environment (JRE).
Though AWS S3 v2 connexion natively supports reading JSON files, in that location are limitations in reading complex JSON files. Hence to process complex JSON files, the best way is through Java transformation.
Refer the requirements and limitations in performing the Indirect loading of files from S3 bucket folders from linked article in in a higher place department.
Related Article: Indirect File Loading in Informatica Deject (IICS)
Source: https://thinketl.com/reading-json-files-from-aws-s3-in-informatica-cloud-iics/
0 Response to "Read and Parse Json File in S3"
Enregistrer un commentaire